GDAN,Question Generation 和 Question Answering 相结合,利用少量的有标注的 QA 对 + 大量的无标注的 QA 对来训练 QA 模型。
Introduction
看到这篇论文,看到来自 CMU,就忍不住推测作者估计是 LTI 的,估计还上过 411/611/711,毕竟 idea 和 final project 太像了。。
回顾下 CMU 11411/611/711 的 final project,项目是阅读理解,分为 Asking System 和 Answering System 两个子系统。17年初的时候,Alan 鼓励用课上学到的东西 & 隐晦的不鼓励用 DL,anyway 那时候也并没有看到用 DL 做 QG 的 paper,网上唯几和 QG 相关的 paper 都是 CMU 的,估计和这门课相辅相成。
611 的 asking system 和 answering system 都没有标注,只是纯粹的 wiki 文本,asking system 基于 document 产生 question 以及 answer,answering system 根据 question 和 document 产生 answer。具体见之前的两篇博文:
NLP 笔记 - Question Answering System
QA system - Question Generation
因为没有标注,所以两个系统其实是相互补充相互促进的。如果产生的 question 太简单,和原文太过相近,那么 answering system 的泛化能力有可能就很差,而如果 question 太难,answering system 也就学很难学习很难训练。
评价产生的 question 的好坏的标准除了流畅、符合语法等基于 question 本身的特点外,我们还希望好的问题能找到答案,这些逻辑在这篇论文中都有所体现。
回到 paper,主要思想其实就是用 少量的有标注的 QA 对 + 大量的无标注的 QA 对 来训练 QA 模型。主要做法是,给部分 unlabelled text,用 tagger 抽一些答案,训练 generative model 来生成对应的问题,然后补充训练集,再训练 QA model。实际是用改进的 GAN 方法来构建一个半监督问答模型。
Model Architecture
Generative Model - seq2seq with attention and copy
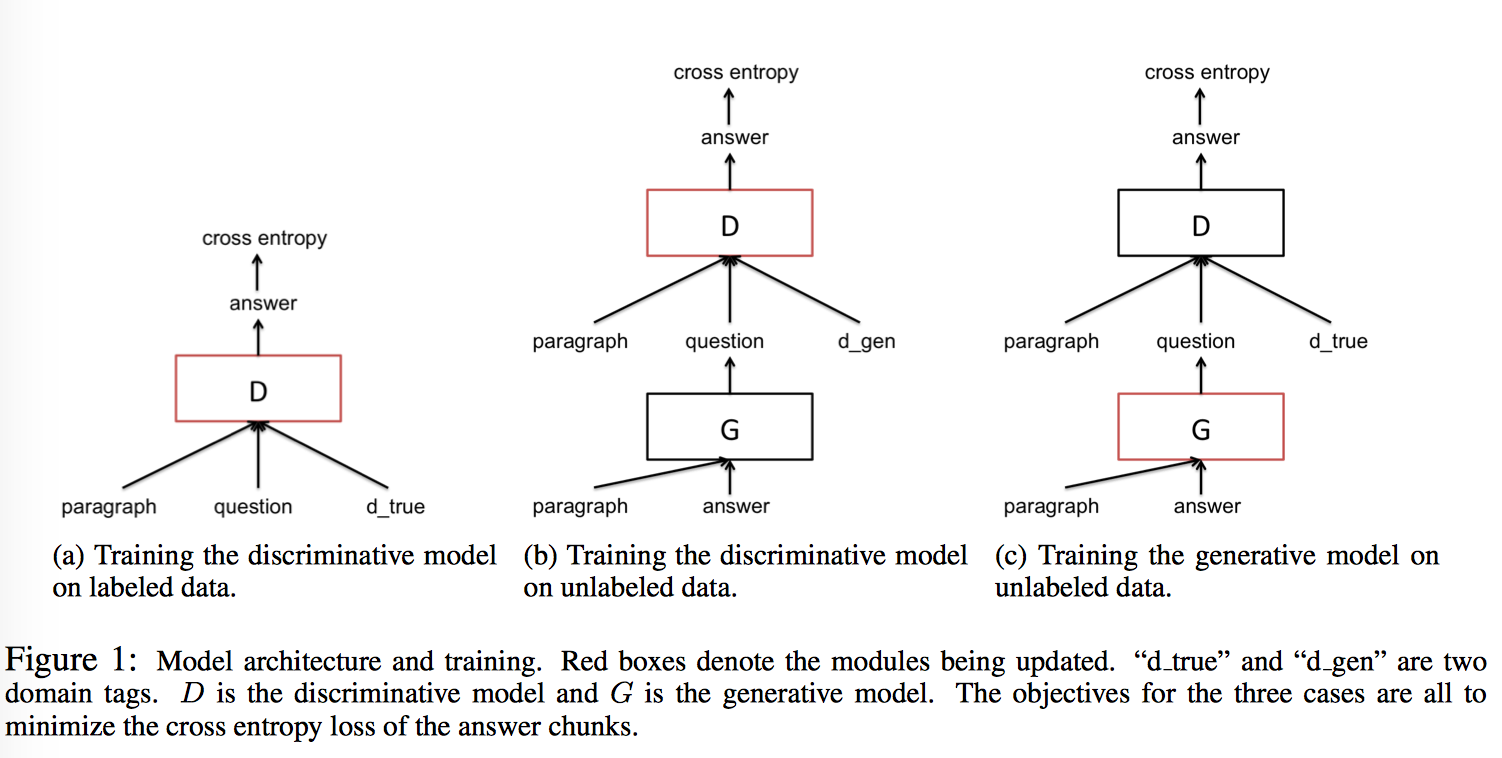
对 P(q|p,a) 进行建模。输入是 unlabelled text p 和从中抽取的答案 a,输出是 q,或者说 (q, p, a)。答案 a 的抽取依赖 POS tagger + constituency parser + NER tagger。生成模型这里用的是 seq2seq model(Sutskever et al., 2014) + copy mechanism(Gu et al., 2016; Gulcehre et al., 2016)。
Encoder 用一个 GRU 把 paragraph 编码成 sequence of hidden states H。注意论文在 paragraph token 的词向量上加了额外的一维特征来表示这个词是否在答案中出现,如果出现就为 1,否则为 0。
Decoder 用另一个 GRU + Attention 对 H 进行解码,在每一个时刻,生成/复制单词的概率是:
$$P_{overall} = g_tp_{vocab}+(1-g_t)p_{copy}$$
$$g_t=\sigma(w^T_gh_t)$$
具体细节不多说了,相关可以看 Copy or Generate。
生成模型 G 产生的 (q, p, a) 作为判别模型的输入。
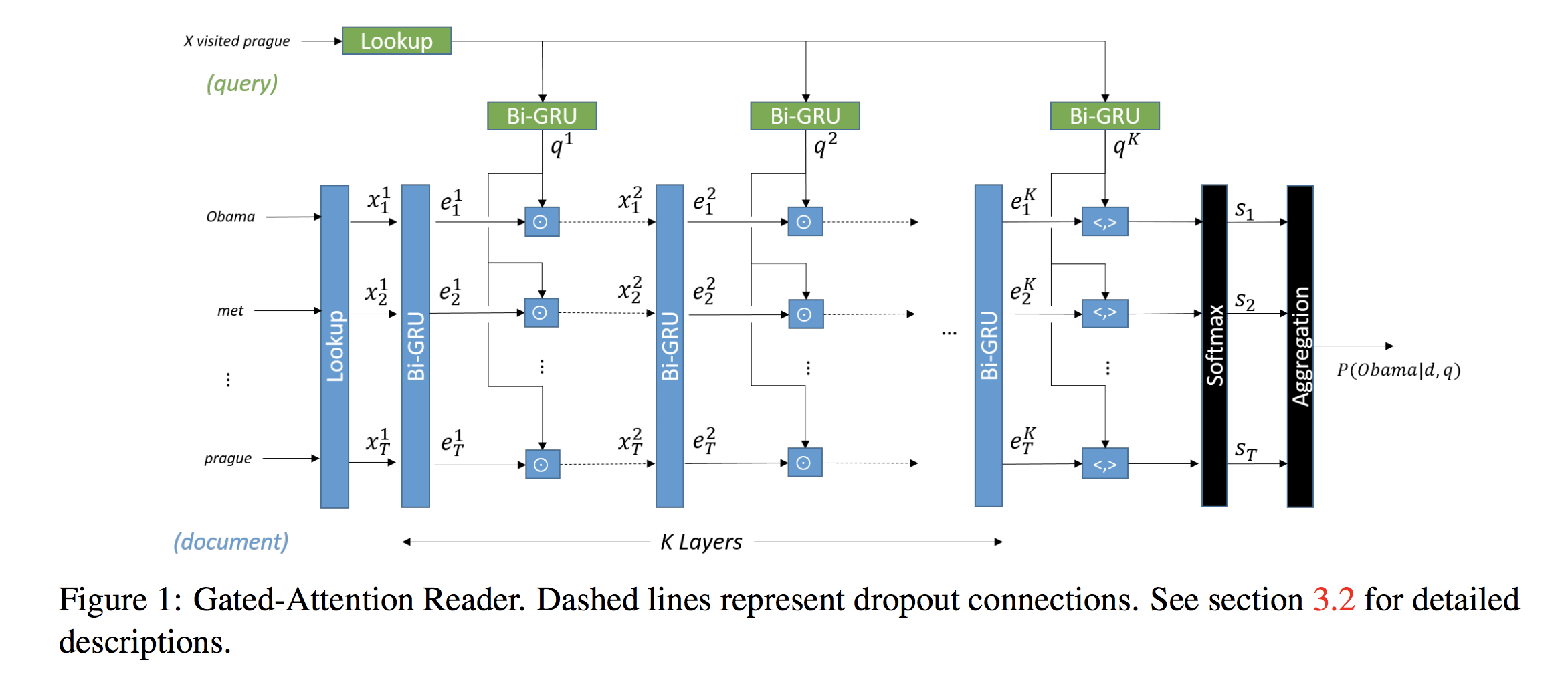
Discriminative Model - gated-attention reader
对 P(a|p,q)进行建模。输入是人为标注数据 L 以及模型产生的数据 U,由于 L 和 U 来自不同分布,所以引入了 domain tag 来区分两类数据,“true”来表示人为标记数据 L,“gen”标签来表示模型生成数据 U(Johnson et al., 2016; Chu et al., 2017)。在测试时,只加入 d_true。
论文这里用了 GA (gated-attention) Reader 作为基本结构,也是 CMU 出的模型,当然事实上别的模型也可以。模型很简单,embedding 层用词向量,encoder 层用双向 GRU 分别得到 $H_q$ 和 $H^k_p$,context-query attention 层用 gated attention($H^k_p$, $H_q$ 做 element-wise 乘法)做下一层网络的输入,重复进入 encoder 和 attention 层进行编码和乘法(共 k 层),最后将 p, q 做內积(inner product)得到一个最终向量输入 output 层,output 层用两个 softmax 分别预测答案在段落中的起始和结束位置。
Loss function
整体的目标函数:
$$max_D \ J(L, d_{true, D})+ J(U_G, d_{gen}, D)$$
$$max_G \ J(U_G, d_{true}, D)$$
Training Algorithm
主要要解决下面两个问题。
Issue 1: discrepancy between datasets
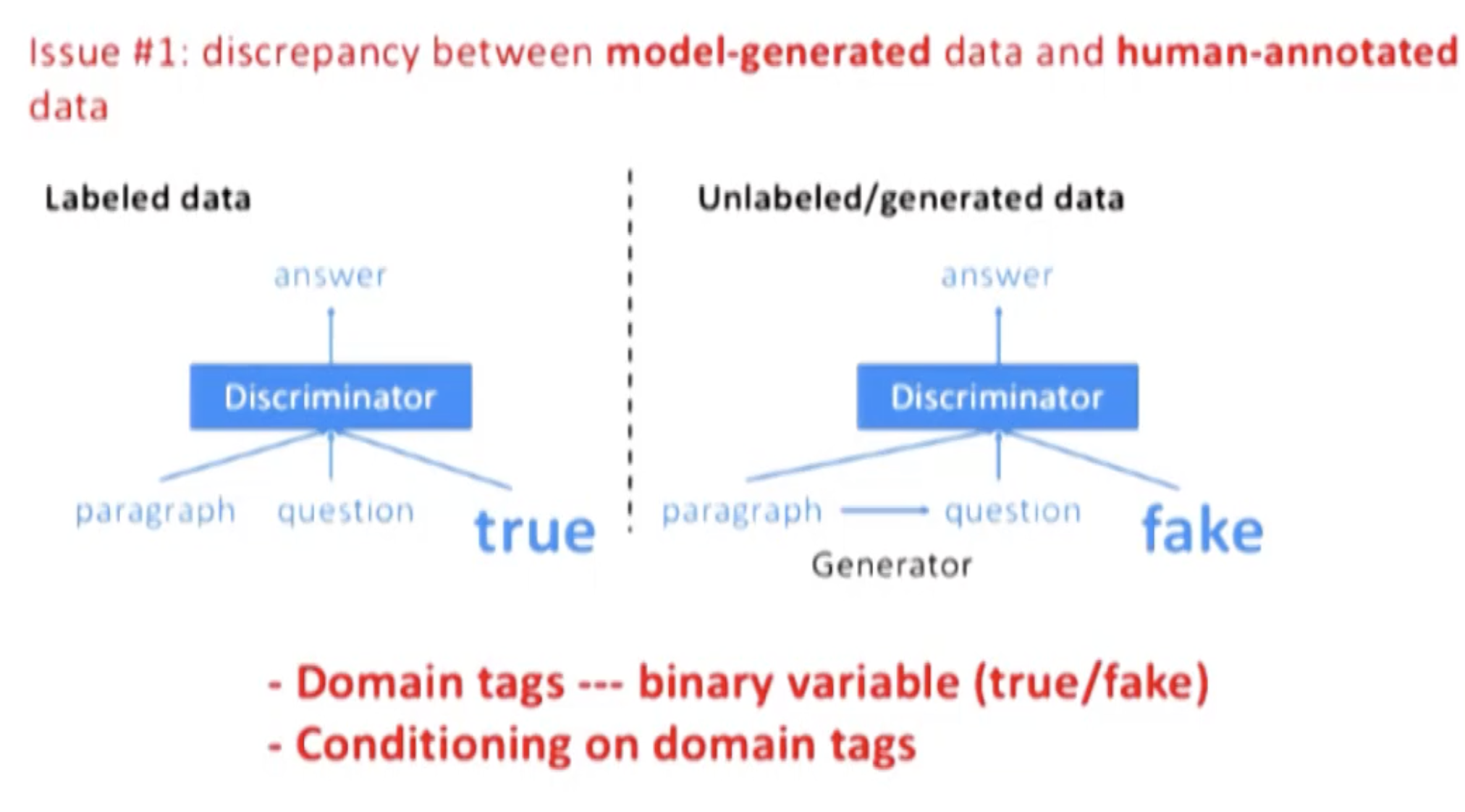
如上,判别模型很容易在 U 上 overfit,所以才用了 domain tag 做区分。
Issue 2: jointly train G and D
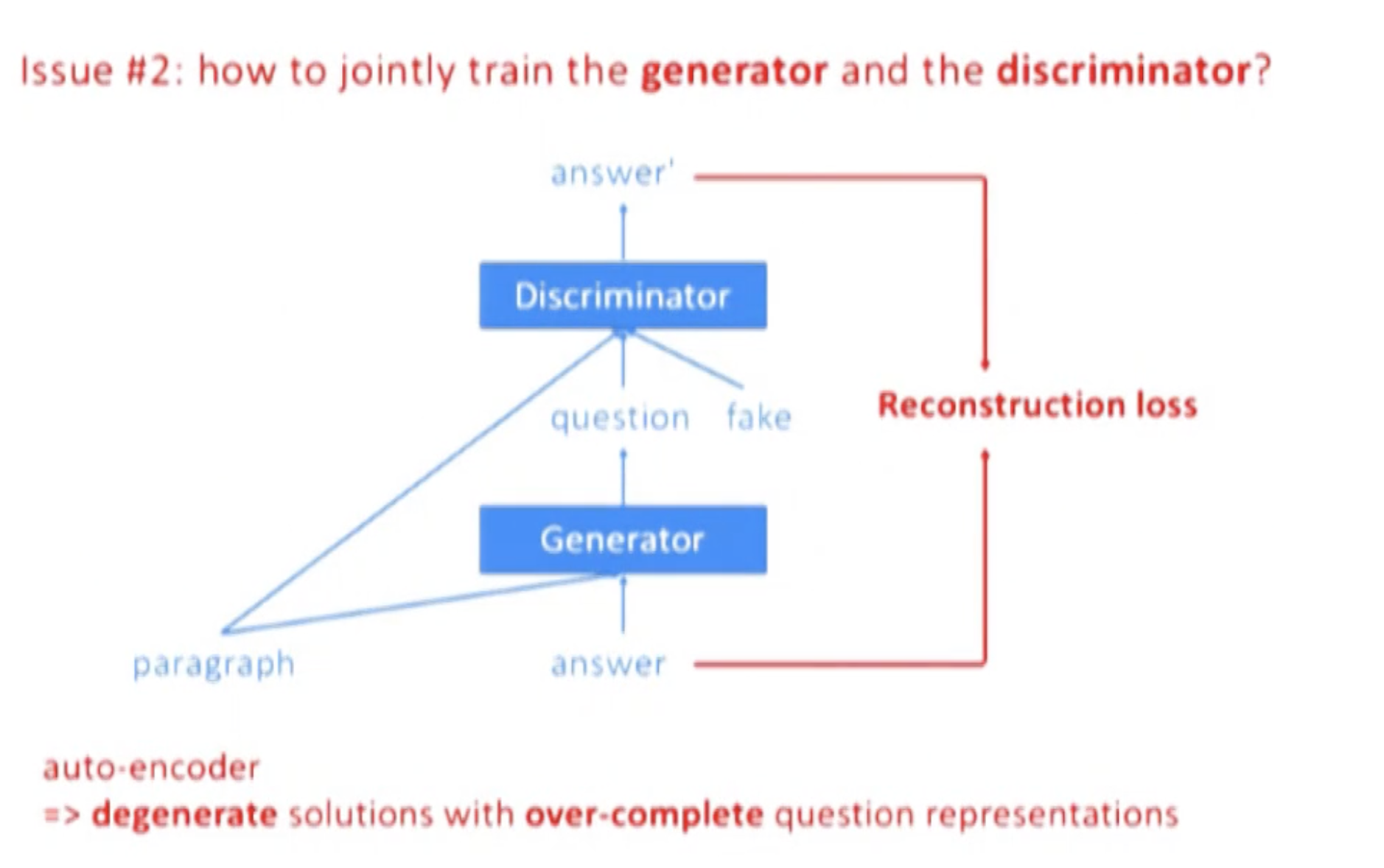
如上,如果用 auto-encoder,容易让 question 和 answer 的表达非常接近,question 甚至可能完全 copy answer,所以这里用了判别模型。
Intuitively, the goal of G is to generate “useful” questions where the usefulness is measured by the probability that the generated questions can be answered correctly by D
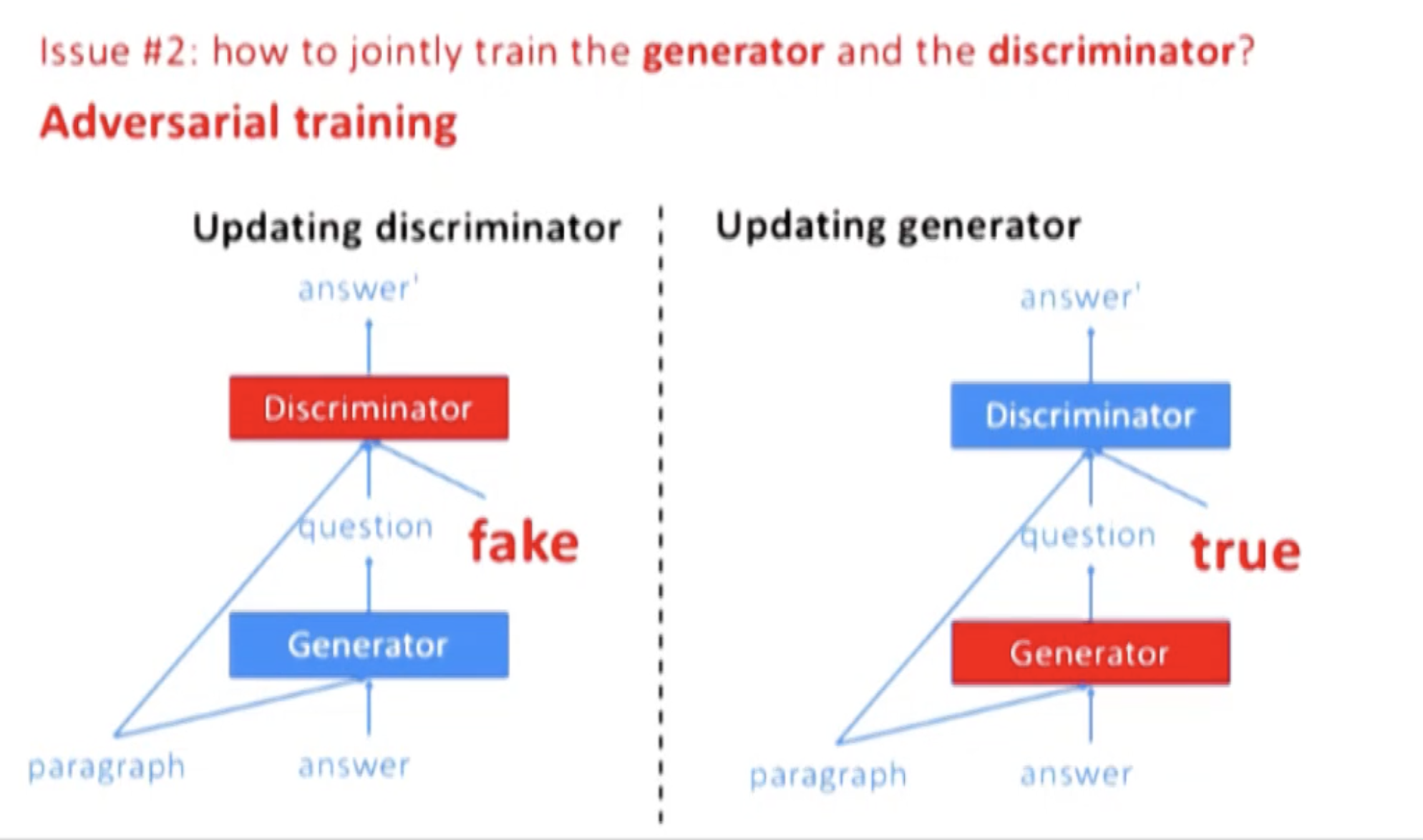
Algorithm
分两个阶段:
第一阶段: 固定 G,利用 d_true 和 d_gen,用 SGD 来更新 D。在 L 上计算 MLE 来完成 G 的初始化,对 D 进行随机初始化。
第二阶段: 固定 D,利用 d_true,用 RL 和 SGD 更新 G。由于 G 的输出是不可导的,所以用到了 reinforce algorithm。action space 是长度为 T’ 的所有可能的 questions,reward 是 $J(U_G,d_{true}, D)$。

Summary
QANet 那篇论文中提到了另一篇 Question Generation 的论文:
Zhou et al. (2017) improved the diversity of the SQuAD data by generating more questions. However, as reported by Wang et al. (2017), their method did not help improve the performance.
相信 GDAN 在一定程度上一定能缓解 QA 中标注数据稀少的问题,但是能否在数据较为充足,模型较为优势的情况下提升 performance,估计难说,下次尝试后再来填这个坑了。Anyway,看到了曾经思考过的问题有人做出了实践还是万分开心的~

